One of my friend ended up with 4 million additional junk rows in a table due to an application bug. The table originally had around 54 million rows. Since the table was an important one, my friend asked me to delete those junk rows from the table as soon as possible with the following constraints.
- No selective dump and restore because my friend had no exact way of identifying the junk rows
- Cannot restore from backup because this needs downtime of the application. Moreover the table was in slony replication and this means I need to unsubscribe/subscribe the slony set to multiple slaves.
DELETE FROM app_table WHERE row(site_inc_id,ad_inc_id) IN (SELECT site_inc_id, ad_inc_id FROM junk_del); Next I wanted to get a rough estimate on the time taken to run the above query. On running EXPLAIN it revealed that its going to take 1 hour to execute which looked little bit on the higher side.
Digging around we increased the work_mem from the current default of 1MB to 50MB only for this session and as we expected the time reduced to roughly 40 minutes.
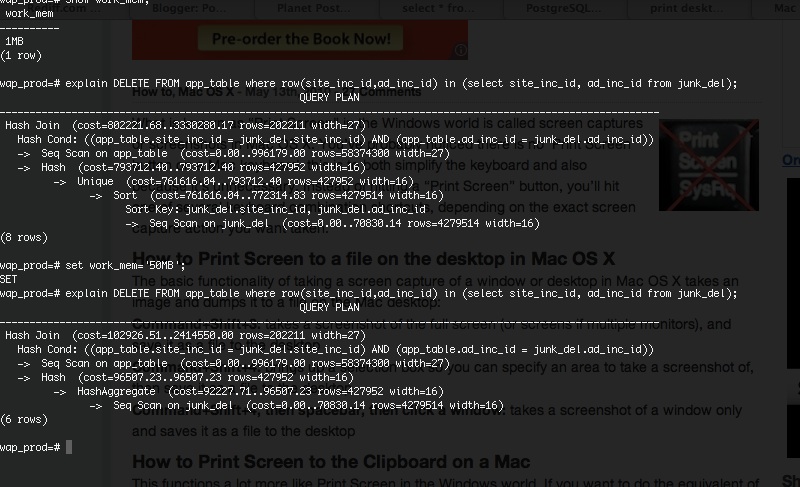
With full joy we executed in production and it finished in just 19 minutes. To summarize increasing work_mem was quick and worthy trick which really helped us. At the end of it my friend was happy for obvious reason.
btw, joining on two variables per table can be quite expensive. Especially if those are variable length keys (text, varchar, etc) as oppose to fixed length ones (int, bigint, etc).
ReplyDeleteGrzegorz J,
ReplyDeleteTrue. To be frank that was a badly designed schema to start with though..
How did you estimate the expected run time (1 hour and then 40 minues)? Because EXPLAIN does not provide anything like that (AFAIK).
ReplyDeleteTomas,
ReplyDeleteIts a rough number based on the cost found in the EXPLAIN. Its rough because even the original query which was estimated to complete in 40 minutes finished in 19 minutes. Basically we saved some time in query execution by avoiding SORTing which is a direct consequence of increasing work_mem.